| Entrez Help Document |
| PubMed | Entrez | BLAST | OMIM | Taxonomy | Structure |
Last modified : September 7, 2000
Nucleotide - Protein - Genome - Structure - PopSet
Welcome to the Entrez Help document. The purpose of this document is to provide assistance in using Entrez on the World Wide Web (WWW). Entrez integrates the scientific literature, DNA and protein sequence databases, 3-D protein structure data, population study data sets, and assemblies of complete genomes into a tightly coupled system. Help using the literature component of Entrez, known as PubMed, is also available. Go to PubMed Help. This help document is organized as follows: Introduction - describes the new Entrez WWW homepage, its databases and features Searching - introduces and demonstrates basic search techniques Refining Your Search - demonstrates advanced search techniques using limits, indexes, and histories and includes help with Writing Advanced Search Statements Displaying and Saving Results - explains the various display formats, how to save results and how to link to related information in other databases Link Out - introduces this newest Entrez feature and explains how to use it The new PubMed/Entrez homepage
Available databases are shown on the black menu bar across the top of the page, beneath the NCBI logo. Your choices are: PubMed, Nucleotide, Protein, Structure, Genome, and PopSet. The scope of these databases is explained in the Database section of this introduction. The available databases are also displayed on the "Search" pull-down menu as shown below. Databases are selected from the black menu bar or the pull-down menu. In this example, PubMed is the chosen database as shown on the pull-down menu and the large "PubMed" at the top of the page adjacent to NCBI (National Center for Biotechnology Information) and and National Library of Medicine (NLM).
The search query box appears directly beneath the "Search" pull-down menu. Search terms are typed into this box and executed by selecting the "Go" button (or by pressing the "return" button on your computer keyboard). The "Clear" button erases search terms in the query box. Use it to begin a new search. There are links to Limits, Index, History, and Clipboard below
the search query box. These are defined in this introduction and summarized
in the Summary
Matrices at the end of this introduction. See also the Using
Limits, Using the Indexes, Using
Your History, and Details
Button, Add To Clipboard, and Save sections of this document for more
information.
Nucleotide DatabaseThe Nucleotide database contains sequence data from GenBank, EMBL, and DDBJ, the members of the tripartite, international collaboration of sequence databases. EMBL is the European Molecular Biology Laboratory (EMBL) at Hinxton Hall, UK, DDBJ is the DNA Database of Japan (DDBJ) in Mishima, Japan. Sequence data is also incorporated from the Genome Sequence Data Base (GSDB), Santa Fe, NM. Patent sequences are incorporated through arrangements with the U.S. Patent and Trademark Office (US PTO), and via the collaborating international databases from other international patent offices.Protein DatabaseThe Protein database contains sequence data from the translated coding regions from DNA sequences in GenBank, EMBL and DDBJ as well as protein sequences submitted to PIR, SWISSPROT, PRF, Protein Data Bank (PDB) (sequences from solved structures).Genome DatabaseThe Genomes database provides views for a variety of genomes, complete chromosomes, contiged sequence maps, and integrated genetic and physical maps.Structure DatabaseThe Structure database or Molecular Modeling Database (MMDB) contains experimental data from crystallographic and NMR structure determinations. The data for MMDB are obtained from the Protein Data Bank (PDB). The NCBI has cross-linked structural data to bibliographic information, to the sequence databases, and to the NCBI taxonomy.Use the NCBI 3D structure viewer, Cn3D, for easy interactive visualization of molecular structures from Entrez. PopSet DatabaseThe PopSet database contains aligned sequences submitted as a set resulting from a population, a phylogenetic, or mutation study describing such events as evolution and population variation. The PopSet database contains both nucleotide and protein sequence data.Database InterlinkingWhat makes Entrez more powerful than many services is that most of its records are linked to other records, both within a given database (such as Nucleotide) and between databases. Links within a database are called "neighbors" (e.g., Nucleotide neighbors).Protein and Nucleotide neighbors are determined by performing similarity searches using the BLAST algorithm to compare the entry amino acid or DNA sequence to all other amino acid or DNA sequences in the database. Links between databases are also possible. Nucleotide sequence records in the Nucleotide database are linked to the PubMed citation of the article in which the sequences were published. Protein sequence records are linked to the nucleotide sequence from which the protein was translated. See Displaying and Saving
Results for more information on links within and between databases.
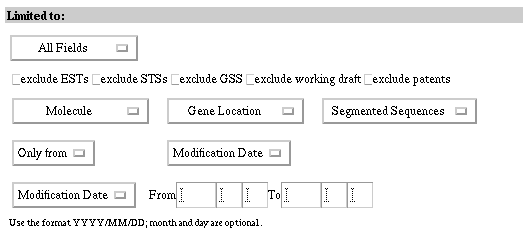
Limits are ways to restrict a search to a defined subset of the database. Limits can be set to restrict a search to a particular database field (e.g., the author field). Limits can be set to search everything but a particular type of data (e.g., exclude patent records). Alternatively, limits can be set to only search a particular type of data (e.g., Genomic RNA/DNA) or to only search data from a particular source (e.g., EMBL). Date limits and sequence length limits are also possible. The nature of Limits makes them dependent on the database fields. Because the Entrez databases are different, Limits available for each database are also different. See the Limits Available by Database Summary in the Summary Matrices section of this introduction. See also the Using Limits section of this document for help in using limits in your search. Limits available for the Nucleotide database
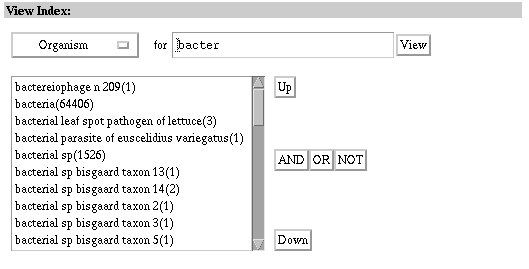
Indexes are alphabetical lists of terms from searchable database fields. When indexes are displayed, they provide a way to browse the terms by which records and/or data are described. Entrez not only lets you browse indexes, you can also select terms to search directly from them. As with limits, the indexes available for a particular database are dependent on the searchable fields of that database. See the Indexes Available by Database in the Summary Matrices section of this introduction. The view below displays the entries listed alphabetically under "bacter" in the "Organism" index of the Nucleotide database. Specific indexes are selected from the "View Index" pull-down menu. Indexes are searchable by typing search terms in the query box. They are also browsable by selecting the "Up" and "Down" buttons to scroll. See the Using the Indexes section of this document for help in using indexes in your search. Nucleotide database "All Fields" Index
Available indexes for the Nucleotide database are shown below. Nucleotide "View Index" pull-down menu
History provides a record of the searches performed during a search session. Histories are database specific. Each time search terms are typed into the query box and the search is executed, the search terms, the time the search was executed and the search results are saved automatically in the History for that database. Additionally, each search is numbered. The History can be recalled at any time during a search session, but histories are lost after one hour of inactivity. Histories can be used to review, revise or combine the results of earlier searches. See the Using Your History section of this document for help in using your search history. The History of a search session in Nucleotide database
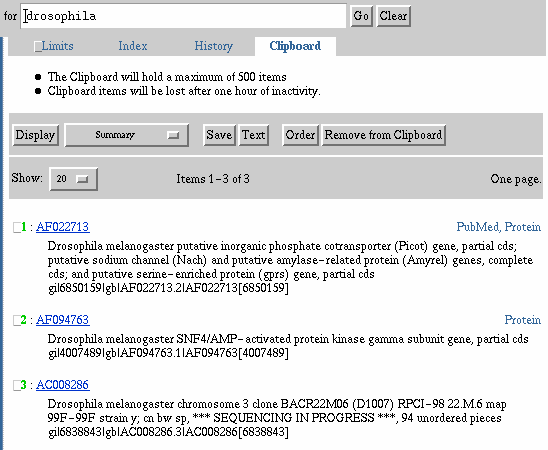
The Clipboard is a temporary place where search results can be saved by users. Clipboards are database specific. Search results are not saved automatically. Each database clipboard is limited to 500 items and items saved to the clipboard are lost after one hour of inactivity. Items can be displayed and saved from the Clipboard. See Details Button, Add To Clipboard, and Save section of this document for help in adding records to and using records on your clipboard. A Clipboard from the Nucleotide database
Select an Entrez database and enter one or more search terms in the query box (e.g., 16S RNA). Query Box for Nucleotide Database
Subject terms are automatically combined (ANDs). In the example above
the search query - 16S RNA retrieves all records with the terms 16S AND
RNA. See Boolean Operators for more information
on combining terms with Boolean Operators.
To force Entrez to search for a phrase enter double quotes (" ") around the phrase. For example, "16S RNA" retrieves only 86 documents compared to the subject search 16S AND RNA that retrieves more than 24,000 documents. Using quotes forces Entrez to check a phrase list against which the search terms are matched. It is not adjacency searching. If the search phrase is not in the phrase list, Entrez treats the terms as though they are not in quotes and automatically combines them (AND). Although phrase searching is useful it should be used with caution
because enclosing search terms in quotes restricts the documents retrieved
to only those documents with exact matches to the text string within the
quotes. In this example, documents with the term 16S RNA are retrieved
but documents with the term 16S RNA gene are not.
Enter author names in the format: last name plus initials (e.g., johnson
d). Do not use punctuation. This format instructs Entrez to search only
the author field. Entrez automatically truncates on the author's name to
account for varying initials and designations such as Jr. or 2nd. If only
a last name is used in the query box (e.g., johnson), Entrez will search
All Fields for that term.
Unique identifiers can be accession numbers, which apply to a
complete sequence record, or sequence identification numbers, which
apply to the individual sequences within a record.
There are two types of sequence identification numbers:
a series of digits that are assigned consecutively by NCBI to each sequence it processes consist of the accession number followed by a dot and a version number If a sequence changes in any way, it receives a new GI number, and the version number is incremented by one. The Sample GenBank Record contains additional detail about GI and Version sequence identification numbers.
NCBI implemented a new "Molecular Weight" search field in July 2000 for searches of the Entrez Proteins database at the request of the mass spectrometry group at NIH. Dr. Lewis Pannell provided technical advice.The Molecular Weight field can be queried as a single molecular weight: 002002 [Molecular Weight]or a range of weights: 002002:002009 [Molecular Weight]or either expression can be combined with other Entrez search terms, for example, to limit by organism: 002002:002009 [Molecular Weight] AND human [Organism]Note that molecular weight must be entered as a fixed 6 digit field, filled with leading zeros (not letter O). The square brackets can contain the full spelling of the search field, as in the examples above, or the abbreviation [MOLWT] in upper or lower case.Note also that where cleavage products are annotated with features, the molecular weight of each cleavage product is calculated, not the molecular weight of the whole protein. Thus you may retrieve a large protein when querying with a small molecular weight -- be sure to check the feature table of the protein record to see if it has cleavage products.How the Molecular Weight is calculated:
Z means E or Q -- molecular weight is calculated as E
Range searching can be done on three data elements: accession numbers
[ACCN], sequence length [SLEN], and molecular weights [MOLWT]. The range
operator is the colon (:), and the appropriate field qualifier should be
included in square brackets after the second term. Field qualifiers are
case insensitive, so either [ACCN] or [accn] will work. It is not necessary
to include a space between the search term and the field qualifer, although
that can be done, if desired.Example searches: Range of accession numbers:
Truncating search terms is a convenient way to find all the records
that contain terms that begin with a given text string. Place an asterisk
(*) at the end of a search term to find all records with a term that begins
with that text string. For example, the truncated search term "immunoglob*"
will retrieve all records in the database that contain the word immunoglobulin,
immunoglobulins, immunoglobin, and immunoglobins.
Entrez searches the first 150 variations of a truncated term.
If a truncated term produces more than 150 variations, which is possible
with terms like "bact*," Entrez gives the following warning:
"Wildcard search for 'bact*' used only the first 150 variations.
Lengthen the root word to search for all endings."
Phrases that include a space in the word after the asterisk will
NOT be retrieved. For example, if you search "chromo*," the documents retrieved
will contain terms like chromobacterium but not chromo helicase.
Left-handed truncation is not possible (e.g., "*bacterium").
Use your search History to combine documents retrieved with different
search terms at different times during your search session. For example,
search the Nucleotide database for HIV. This search retrieves 37,549 documents.
Now search the Nucleotide database for protease. This search retrieves
13,061 documents. Now click on the History for the Nucleotide database.
The results for the HIV and protease search terms are saved as Search
Sets #1 and #2, respectively. In the query box, type #1 AND #2 and select
Go. This search combines the documents in Search Set #1 (HIV) with the
documents in Search Set #2 (protease) and retrieves only those documents
that are in both sets (i.e., 3,156 documents).
Click on History again and note Search Set #3 (#1 AND #2).
Remember, this History is for the Nucleotide database only and
it will be lost after one hour of inactivity. See Boolean
Operators and Using Your History
for more information and examples.
Sometimes it is necessary to refine your search statement by using the
Limit, Index and History options of a given Entrez database. The key to
using these options, especially the Limit and Index options, is a better
understanding of the Entrez databases' search
fields and Boolean Operators.
Boolean Operators used in Entrez are:
AND: To AND two search terms together instructs Entrez
to find all documents that contain BOTH terms.
OR: To OR two search terms together instructs Entrez to
find all documents that contain EITHER term.
NOT: To NOT two search terms together instructs Entrez
to find all documents that contain search term 1 BUT NOT search term 2.
The Entrez search rules and syntax for using Boolean operators
are:
1. Boolean operators, AND, OR, NOT must be entered in UPPERCASE
(e.g., promoters OR response elements).
2. Entrez processes all Boolean operators in a left-to-right sequence.
The order in which Entrez processes a search statement can be changed by
enclosing individual concepts in parentheses. The terms inside the parentheses
are processed first as a unit and then incorporated into the overall strategy.
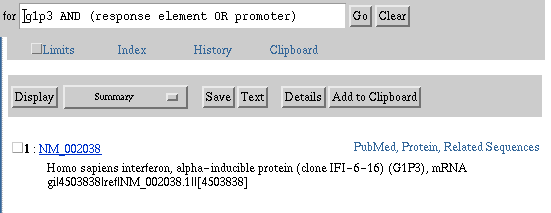
For example, the search statement: g1p3 AND (response element OR promoter)
is processed by Entrez by ORing the terms response element OR promoter
first and then ANDing the resulting set of documents with g1p3.
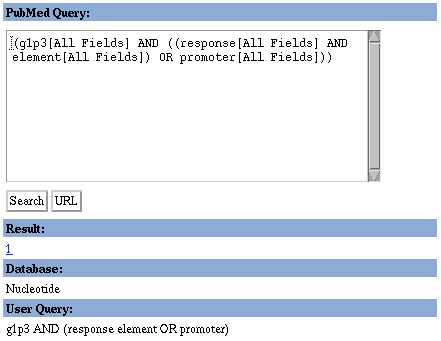
3. Click on the Details button to see how Entrez translated and
executed your search strategy.
4. See Writing Advanced
Search Statements for more information on using Boolean Operators and
Entrez Search Field Qualifiers.
Details Button
Details Screen
Limits are used to refine search results to retrieve only the most relevant
documents. In other words limits remove unneeded or unwanted documents.
This section provides examples for using limits to:
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Select Limits.
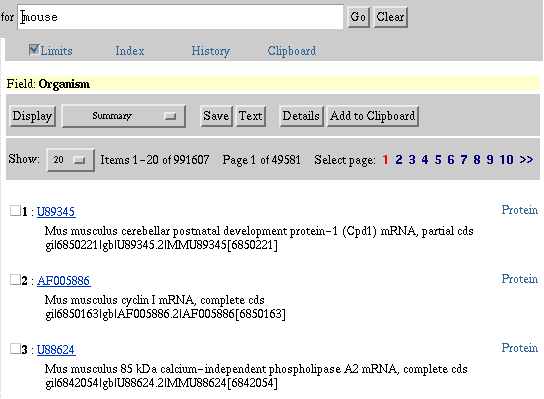
3. In the "Limited To:" section, select Organism from the Search
Field pull-down menu.
4. Type "mouse" without quotes in the query box and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Field:
Organism).
Searching for "Mouse" in the Organism Search Field
Example: You are only interested in protein sequences that
are less than 50 amino acids in length:
1. Select the Protein database from the black menu bar or the
Search pull-down menu.
2. Select Limits.
3. In the "Limited To:" section, select Sequence Length from the
Search Field pull-down menu.
4. Type "0:50" without quotes in the query box and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Field:
Sequence Length).
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Type "mitochondrial carrier" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, check the box next to "Exclude
ESTs" and select Go.
On the results screen note note that the check box next to Limits
is checked indicating that limits are selected and active. Beneath the
check box the selected and active limits are highlighted in yellow (i.e.,
Limits: Exclude ESTs).
In the Nucleotide database you can exclude EST, STS, GSS, working
drafts, and/or Patent sequences. In the Protein database you can exclude
Patent sequences.
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Type "cryptosporidium" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, select the "Molecule" pull-down
menu and choose rRNA and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Limits:
rRNA).
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Type "flowering plants" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, select the "Gene Location" pull-down
menu and choose Chloroplast and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Limits:
Chloroplast).
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Type "cftr" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, select the "Segmented Sequences"
pull down menu and choose show only master of set and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Limits:
Show only master of set).
Please note that this option does not allow you to limit the documents
retrieved to only those containing segmented sequences. It simply allows
you to control how segmented sets of sequences are displayed.
1. Select the Protein database from the black menu bar or the
Search pull-down menu.
2. Type "cysteine phosphatase" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, select the "Only From" pull-down
menu and choose PIR and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Limits:
PIR).
1. Select the Nucleotide database from the black menu bar or the
Search pull-down menu.
2. Type "pigs" without quotes in the query box.
3. Select Limits.
4. In the "Limited To:" section, select Organism from the Search
Field pull-down menu.
5. And in the "Limited To:" section, select the "Modification
Date" pull down menu and choose 30 days and select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Field:
Organism, Limits: 30 days).
Example: You want to retrieve all mouse or human protein
sequences added to the database (or updated) during 1997.
1. Select the Protein database from the black menu bar or the
Search pull-down menu.
2. Select Limits. 3. Type "mouse OR human" without quotes in the
query box.
4. Select Limits.
5. In the "Limited To:" section, select Organism from the Search
Field pull-down menu.
6. And in the "Limited To:" section, select the "Modification
Date" pull down menu and choose Modification Date (as opposed to Publication
Date). In the date boxes, type the dates in the format YYYY/MM/DD. You
can tab from box to box in the date fields. The From date is 1997/01/01
and the To date is 1997/12/31. Select Go.
On the results screen note that the check box next to Limits is
checked indicating that limits are selected and active. Beneath the check
box the selected and active limits are highlighted in yellow (i.e., Field:
Organism, Limits: Modification Date, from 1997/01/01 to 1997/12/31).
Example: You are interested in the protein translations
of human GenBank nucleotide sequences added to the protein database (or
updated) in the last 30 days. You do not want patent records.
1. Select the Protein database from the black menu bar or the
Search pull-down menu.
2. Select Limits. 3. Type "human" without quotes in the query
box.
4. Select Limits.
5. In the "Limited To:" section, select Organism from the Search
Field pull-down menu.
6. On the same screen, select the exclude patents check box, select
GenBank from the Only From pull-down menu, and finally select 30 days from
the Modification Date pull-down menu and select Go.
On the results screen note that the check box next to Limits is checked
indicating that limits are selected and active. Beneath the check box the
selected and active limits are highlighted in yellow (i.e., Field: Organism,
Limits: Exclude patents, 30 days, GenBank).
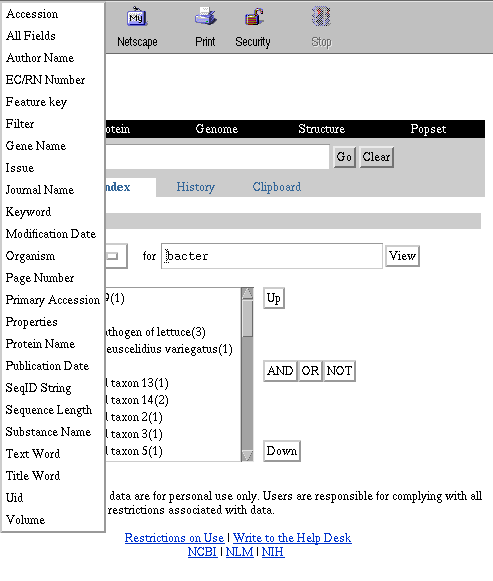
Indexes are used to browse and/or select the terms by which records
and/or data are described. This section provides examples for using indexes
to:
1. Select the Nucleotide database.
2. Select Index.
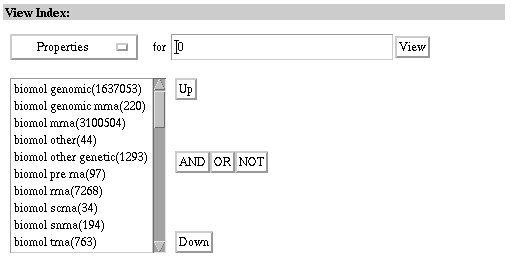
3. Select the Properties index from the View Index pull-down menu.
4. Type "0" (the number zero) without quotes in the View Index
query box and select View.
Because index entries are listed alphabetically, the number zero
instructs Entrez to begin the index display at the very first entry (i.e.,
biomol genomic).
The first few entries of the Nucleotide database's Properties
index
Use the scroll bar to view further entries. Use the "Down" and
"Up" buttons to display the next set of entries in either direction. The
Properties search field and its corresponding index are very useful. This
field contains information about the GenBank division to which the record
belongs (i.e., gbdiv inv). It also describes the molecule type and location.
The Properties field also describes such things like whether the sequence
is part of a population study or segmented set.
Compare the Nucleotide database's Properties index to the Properties
index of the other databases. A Properties index is not available for the
Structure database.
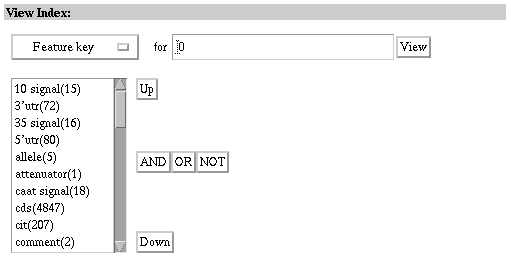
Example: Examine the kind of information indexed in the
Genome database's Feature key index.
1. Select the Genome database.
2. Select Index.
3. Select the Feature key index from the View Index pull-down
menu.
4. Type "0" (the number zero) without quotes in the View Index
query box and select View.
The first few entries of the Genomes database's Feature key index
Use the scroll bar to view the entries. Use the "Down" and "Up"
buttons to display the next set of entries in either direction. The Feature
key search field and its corresponding index are also very useful. This
field contains information about the biological features of the nucleotide
sequences as annotated by submitters and database staff. For more information
on the Feature key field, please see the Feature Table Definitions at at
.....
Compare the Genome database's Feature key index to the Nucleotide
and PopSet databases' Feature key index. Feature key indexes are not available
for the Protein and Structure databases.
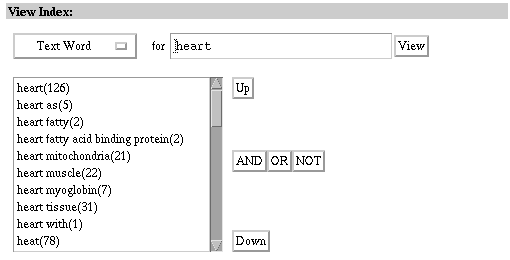
Example: Go directly to an entry in the Structure database's
Text Word index.
1. Select the Structure database.
2. Select Index.
3. Select the Text Word index from the View Index pull-down menu.
4. Type "heart" without quotes in the View Index query box and
select View.
Entries found under "heart" in the Structure database's Text Word
index
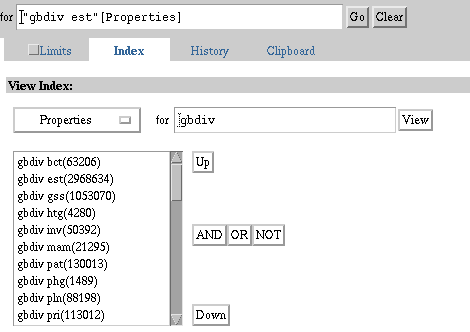
The GenBank divisions are indexed in the Properties field of the
Nucleotide and Genome databases. ESTs are found in the Nucleotide database.
1. Select the Nucleotide database.
2. Select Index.
3. Select the Properties index from the View Index pull-down menu.
4. Type "gbdiv" without quotes in the View Index query box and
select View.
5. View the list of entries and locate the "gbdiv est" entry.
6. Select the gbdiv est entry by clicking on it once.
7. Select the gbdiv est entry as a search term by clicking "AND."
Note that the term is now located in the Search query box as "gbdiv est"[Properties].
8. Select Go to execute this search.
Browsing, selecting and searching from the Nucleotide database's
Properties index
1. Select the PopSet database.
2. Select Index.
3. Select the Organism index from the View Index pull-down menu.
4. Type "human" without quotes in the View Index query box and
select View.
5. View the list of entries and locate the "human" entry.
6. Select the "human" entry by clicking on it once.
7. Select the "human" entry as a search term by clicking "AND."
Note that the term is now located in the Search query box as "human" [Organism].
8. Type "mouse" without quotes in the View Index query box and
select View.
9. View the list of entries and locate the "mouse" entry.
10. Select the "mouse" entry by clicking on it once.
11. Select the "mouse" entry as a search term by clicking "OR."
Note that the term is now located in the Search query box with the human
term (i.e., "human"[Organism] OR "mouse"[Organism]).
12. Repeat steps 8-11 above for drosophila so that the final search
statement in the query box is:
"human"[Organism] OR "mouse"[Organism] OR "drosophila"[Organism]
13. Select Go to execute this search.
1. Select the Protein database.
2. Select Index.
3. Select the Organism index from the View Index pull-down menu.
4. Type "pig" without quotes in the View Index query box and select
View.
5. View the list of entries and locate the "pig" entry.
6. Select the "pig" entry by clicking on it once.
7. Select the "pig" entry as a search term by clicking "AND."
Note that the term is now located in the Search query box as "pig" [Organism].
8. Select the Text Word index from the View Index pull-down menu.
9. Type "kinase" without quotes in the View Index query box and
select View.
10. View the list of entries and locate the "kinase" entry.
11 Select the "kinase" entry by clicking on it once.
12. Select the "kinase" entry as a search term by clicking "AND."
Note that the term is now located in the Search query box as "kinase" [Text
Word] and that the final search statement in the query box is:
"pig"[Organism] AND "kinase"[Text Word]
13. Select Go to execute this search.
REMEMBER that Entrez processes complex search statements using
Boolean Operators in a specific order as described in the Boolean
Operators section above. You can always check the Details button to
see how your final search statements are executed.
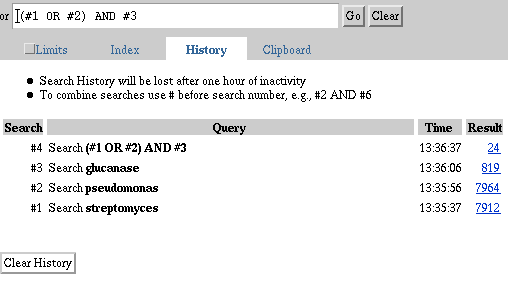
History provides a record of the searches performed during a search
session. This section provides examples for using your search history to:
1. Select the Protein database.
2. Type "streptomyces" in the query box and select Go.
3. Select Clear.
4. Type "pseudomonas" in the query box and select Go.
5. Select Clear.
6. Type "glucanase" in the query box and select Go.
7. Select History.
8. Review your search History and results. Note that each search
statement is numbered. Also note the time and number of results for each
search statement.
9. Combine the results of your earlier searches using the search
numbers and Boolean operators. For example: (#1 OR #2) AND #3. Select Go.
10. Select History to once again review your search History and results.
Protein database Glucanase Search History
Although search Histories are database specific, the History numbering
system is continuous across all databases searched during a singular search
session. For instance, let's say you just finished searching the Protein
database using the example above. Next you want to search the Structure
database for similar information. You cannot use your Protein database
search History in the Structure database. However, as you start searching
the Structure database, Entrez sequentially numbers the search sets based
on the last search query executed in any database. Therefore, in this example,
the first search query executed in the Structure database is numbered search
#30. The next search query executed is numbered search #31 and so on. Entrez
will save a maximum of 100 queries at a time.
A final note on search histories. If you search the same query
in the same database during the same search session, the search set will
only be saved in the History one time. It will be saved under the first
set number not the latter ones.
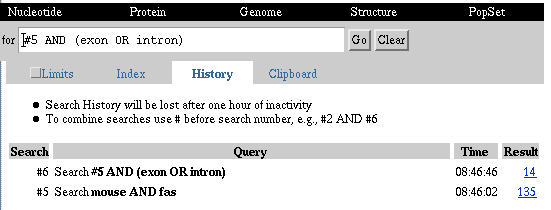
1. Select the Nucleotide database.
2. Type "mouse AND fas" without quotes in the query box and select
Go.
3. The search retrieves 135 documents. You do not want to review
all 135 documents and decide you are really interested in any sequences
with annotated exons or introns.
4. Select History.
5. Refine the results of your search using the search number and
Boolean operators. For example: #5 AND (exon OR intron). Select Go.
6. Select History to once again review your search History and
results. Refining the search has reduced the number of retrieved documents
to 14.
Mouse fas antigen Search History
Complex search statements can be written and executed directly from
the the query box of any of the five databases. As long as you obey some
simple rules and use the correct syntax.
Perform a search by specifying the search terms, their fields,
and the boolean operations to perform on the term. Use the following syntax:
term [field] OPERATOR term [field]
Where term(s) is/are the search terms, the field(s) are the Search
Fields and Qualifiers , and the OPERATOR(s) are the Boolean
Operators. Remember that Boolean operators are normally processed left
to right. If you wish part of your boolean expression to be processed out
of order, enclose it in parentheses.
Example: Find all human nucleotide sequences with D-loop
annotations.
In the Nucleotide database use the following expression -
D-loop[FKEY] AND human[ORGN]
Example: Find all human protein sequences with lengths
between 50 and 60 amino acids and that were entered into the database during
1999.
In the Protein database use the following expression -
human[ORGN] AND 50[SLEN]:60[SLEN] AND 1999[MDAT]
Example: Find drosophila population studies published in
the Journal of Molecular Evolution
In the PopSet database use the following expression -
j mol evol[JOUR] AND drosophila[ORGN]
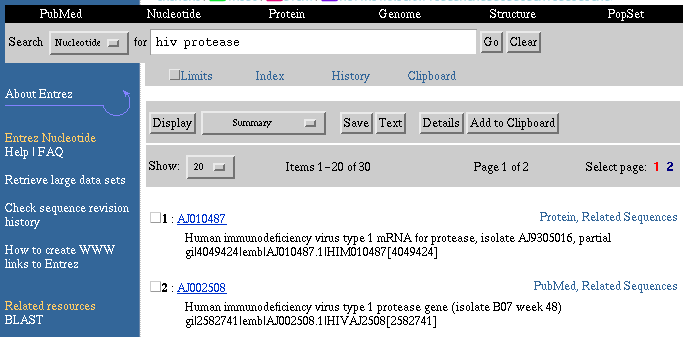
Entrez displays search results as shown below:
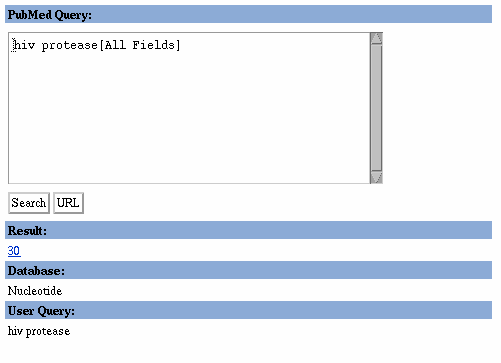
Search results for "hiv protease," Nucleotide Database
The Search query box provides a summary of the database searched
and the search terms as entered (i.e., "Search Nucleotide for hiv protease").
No Limits are applied as the Limits check box is not checked.
Display Button - The default display format is the Summary format shown
in the example above.
To change the Display format, select an alternate format from
the format (i.e., Summary) pull-down menu and click the Display button.
To view the "graphical view" click on the accession number
to display the GenBank report format. On the GenBank report format, click
on the accession number one more time. The Entrez graphical view is displayed.
Alternatively, select the Brief view from the display pull-down menu, click
the Display button. Entrez will provide the graphical view this way as
well.
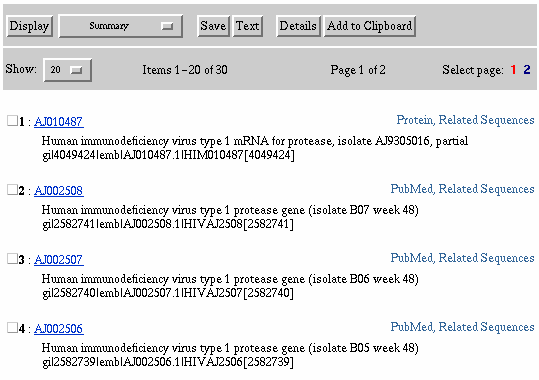
Show Button - The default number of documents displayed is 20. The total
number of pages are displayed to the far right of the Show button (i.e.,
Select page: 1 2). In this example, 30 documents were retrieved and since
we are displaying 20 documents at a time there is a total of two pages.
The Select page: numbers are hotlinked to enable quick navigation from
one page to the next.
To change the number of documents displayed per page, select an
alternate number from the number (i.e., 20) pull-down menu and click the
Display button.
Change the Display button to brief and Show 50 documents per page.
Note that the number of pages changes to one and there are no hotlinks
to other pages since all 30 documents retrieved are displayed on page one.
See the Display
formats table for a summary of the Display formats available by database.
A closer look at the results screen reveals more display options.
Closer Look at Display
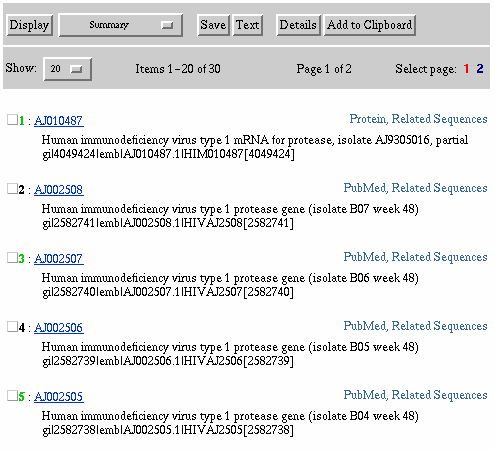
Please note the check box to the left of each numbered result.
Check boxes are used to select individual documents from a set of documents
retrieved. Once selected, the documents can be displayed (in various formats),
saved to the clipboards, or saved to a local disk. Select documents 1,
3, and 5 by clicking the check box. Documents are deselected by unclicking
the check box.
Select Documents Using Check Boxes
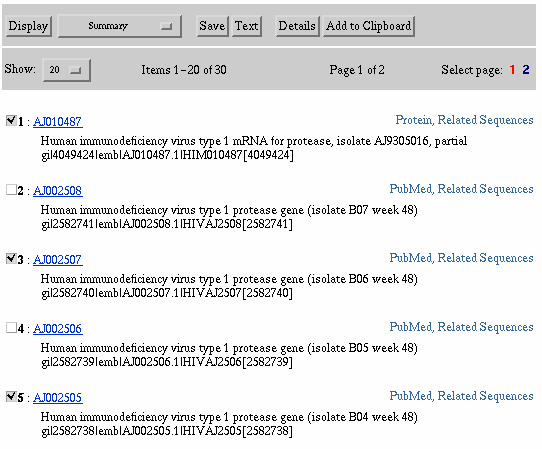
Display documents 1, 3, and 5 in FASTA format by selecting Display
FASTA and then clicking Display.
Display FASTA format of Selected Documents
For a useable FASTA format that can be easily used in other
applications, select the
Text button. The Text button uses your
browser to display the sequence in FASTA format. See the example below.
Copy and paste the sequence from the browser to other applications. Also
see the section below on saving to local disk for information on saving
more useable data formats from Entrez.
The Text Button display of FASTA format of Selected Documents
Also note that on every results display screen, document Accession
numbers are always hotlinked. If selected, these hotlinks also display
the graphical view. In the Structure and PopSet databases, these
links display the Structure and PopSet summaries, not the graphical view.
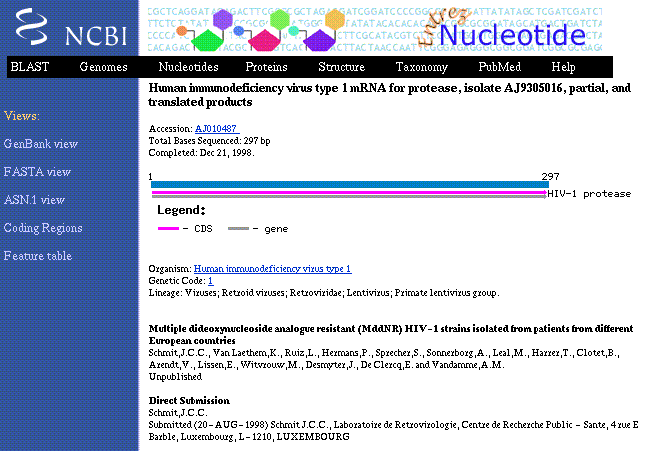
Select the hotlink to the graphical view for Accession Number AJ010487.
>From the Graphic Summary, in the left menu bar, link to the GenBank, FASTA,
or Feature Table.
Display Graphic Summary of Individual Document (AJ010487)
On the Graphic Summary for AJ010487, click on the interval 1 -
297 to see the full graphical presentation, including all annotated features,
of this sequence.
Display Full Graphical View of AJ010487
Finally, note the links to other databases to the far right of
the results display. Select the PubMed link for Accession Number AJ002505.
Display PubMed Link of Individual Document
Details Button - Click the Details button to display your search strategy
as translated using Entrez's search and syntax rules. The Details window
also contains error messages, when applicable. Note that the Details reports
the database searched, the number of documents retrieved (with hotlink
to the documents) and your search statement as written (i.e., not translated
by Entrez). Within the Details window, you can modify and resubmit your
search strategy. Submit the modified search query by selecting the Search
button.
Details Button
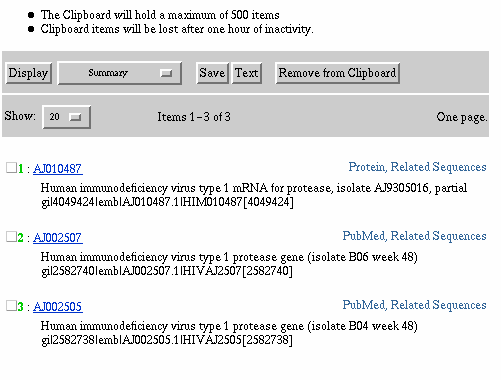
Adding to the Clipboard - Select documents 1, 3, and 5 from the
results set by clicking on the check box adjacent to the document number.
Then click the Add to Clipboard button. Note that 3 items were added to
the Clipboard. You are also reminded that the Clipboard is limited to 500
items and that these three items will be lost after one hour of inactivity
during a single search session. Also, please note that the document numbers
for these items (i.e., documents 1, 3, and 5) are now shown in green to
indicate that they are on the Clipboard. This feature is useful because
as you continue to search, if these documents are retrieved through other
search strategies their document numbers will appear in green to indicate
that they are already on the Clipboard.
Adding to the Clipboard
Retrieving documents from the Clipboard - Select the Clipboard
button. The items on the Clipboard are displayed in the default Summary
format. Note the documents are renumbered, but the numbers are in green
to indicate that the items are on the Clipboard. Also please note that
you can display Clipboard items in all available formats and you can link
to document neighbors or related items in other databases. Items are removed
from the Clipboard by selecting the items using the checkbox and selecting
the Remove from Clipboard button.
Retrieving Items from the Clipboard
Saving to a local disk - Select the Save button at the top (or
bottom) of the results display screen next to the Text button. Documents
can also be saved from the Clipboard in the same manner described here.
Before clicking the Save button, decide two things: Which documents you
want and in what format. After selecting your documents by clicking on
the check boxes and choosing the format using the format pull-down menu,
click the Save button. You are prompted to name the file to which the results
are saved on your local drive. If you do not select specific documents,
all documents in the results set are saved. In the example below, documents
2, 3, 4, 6, and 9 will be saved to disk in the FASTA format. If these documents
were not selected, all 30 documents (i.e., the entire retrieved set) would
be saved to disk in the FASTA format.
Saving Selected Documents to Local Disk
Note that when you need FASTA formatted data, saving to disk provides
the most useable FASTA format available from Entrez. Shown below is one
of the 5 documents saved to disk in FASTA format in the above example.
This format is ready for use in other applications.
>gi|2582741|emb|AJ002508.1|HIVAJ2508 Human immunodeficiency virus
type 1 protease gene (isolate B07 week 48) CCTCARRTCACTCTTTGGCARCGACCCCTCGTCACAATAAAGATAGGGGGGCAACTAAAGGAAGCTCTAT
TAGATACAGRAGCAGATGATACAGTAKTAGAAGAMATRASTTTRCCAGGAAGRTGGAAACCAAAAATGAT
AGGGGGAATTGGAGGTTTTWTCMAAGTAAGACAGTATGATCAGATACTCRTAGAAATCTGTGGRCATAAA
GCTATAGGTACAGTATTAGTAGGACCTACACCTGTCAACATAATTGGAAGAAATCTGTTGACTCAGMTTG
GTTGCACTYTAAATTTT
Printing - Use the Print function of your Web browser. As with
Saving to local disk, before printing, decide two things: Which documents
you want to print and in what format. Because you are using the Web browser
print function, you can only print documents that are displayed. Therefore,
consider increasing the number of documents displayed per page so that
the total number of documents you want to print are displayed on one page.
Print hints: To save paper, consider using the Text or Save buttons before
printing. Doing so will eliminate everything but the actual data you need
(i.e., Entrez search interface, menu bars). If you use the Text button,
print from your web browser. If you use the Save button, print from another
application on your machine.
Linkout is a service that provides links from PubMed citations to full-text
journal articles, biological data, sequence centers, etc. These other resources
provide a URL, resource name, brief description of their web site, which
PubMed uses to create the links to their sites. User registration, a subscription
fee, or some other type of fee may be required to access the full text
of articles in some journals using this feature. Information for developers
is available at:
http://www.ncbi.nlm.nih.gov:80/entrez/query/static/linkoutoverview.html |